我们常看到论文中描述:raw read count 服从泊松分布、负二项分布、零点膨胀的负二项分布等等。 为什么这么说?这是由观察数据的分布与目标分布的概率密度函数(PDF)相近而决定。 例如,不管有没有完美均匀的硬币,人们观察到扔硬币正反面出现次数与泊努利分布的PDF相近,所以认定其服从泊努利分布。 换句话说,数据的性质决定服从什么分布,性质包括:密度、均值、方差、标准差等。 所以有的raw read count 数据更倾向于服从泊松分布,有的更倾向于负二项、零点膨胀的泊松、负二项等等吧。
然而对于raw read count 进行log变换的目的,不是要将负二项分布或泊松分布转为正态分布。 因为
- 有且只有对数正态分布的对数变换之后才是正态分布。(所有文章的作者如果认为负二项分布或泊松分布能转为正态分布,那么其数学就是体育老师教的)
- 泊松或负二项分布在不同分布参数情况下,经过对数变换之后,得到分布可能更接近正态分布、也可能更远离。
- 不论服从泊松还是负二项或者是正态或者二值离散分布,任何分布的数据,经过对数变换之后,精准描述该目的就是放大信号。
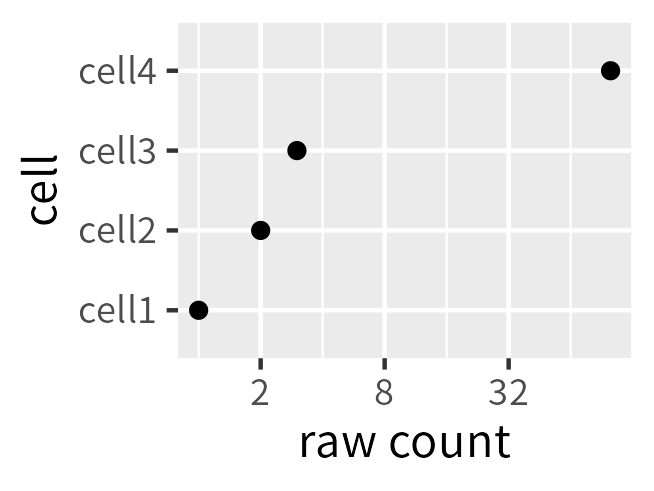
更准确的说是,放大左侧信号、将分布向右偏。 因为当表达值很小左侧数值很小几乎看不出来差异。例如:
count:
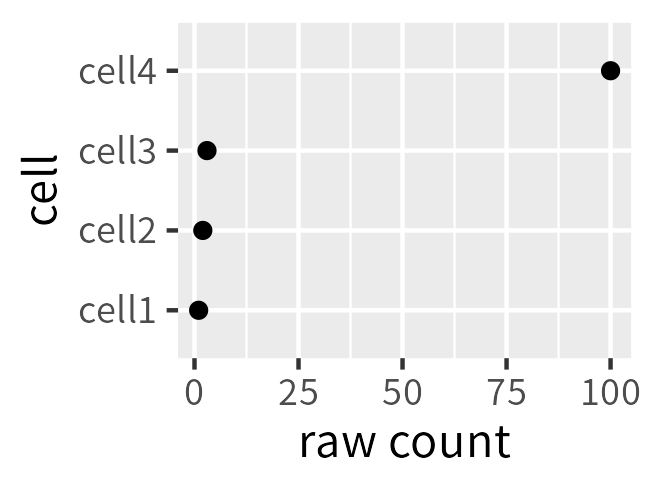
log raw count: